U. Cela donne
une figure, appelée le seuillage de l'image par
l'ensemble U, et notée
SU(I). En la représentant
comme une image binaire (où les pixels de la figure sont
marqués 1 et ceux du fond sont marqués 0), on peut
écrire pour chaque pixel p:
U. Cela donne
une figure, appelée le seuillage de l'image par
l'ensemble U, et notée
SU(I). En la représentant
comme une image binaire (où les pixels de la figure sont
marqués 1 et ceux du fond sont marqués 0), on peut
écrire pour chaque pixel p:
On considère des images à niveaux de gris compris entre g0 et g1 (par exemple, g0 = 0 et g1 = 255). Pour une image I à niveaux de gris, I(p) désigne le niveau de gris du pixel p.
Nous supposons que les images à traiter possèdent la particularité que les objets d'intérêt qu'on souhaite extraire de celles-ci ont généralement leurs niveaux de gris dans un certain ensemble U de valeurs. Ce n'est d'habitude pas le cas pour les photos de scènes 3D (où le niveau de gris est une fonction de la position et de l'intensité des sources lumineuses, ainsi que de la position, de l'orientation et de la réflectance des surfaces). Par contre cela peut souvent l'être pour les images médicales (rayon X, scanner, IRM, etc.), où le niveau de gris donne une indication sur la structure physico-chimique de la zone correspondant au pixel (cfr. l'histogramme montré plus bas).
On peut donc proposer d'extraire les zones d'intérêt en
prenant l'ensemble des pixels p dont le niveau de gris
I(p) U. Cela donne
une figure, appelée le seuillage de l'image par
l'ensemble U, et notée
SU(I). En la représentant
comme une image binaire (où les pixels de la figure sont
marqués 1 et ceux du fond sont marqués 0), on peut
écrire pour chaque pixel p:
SU(I)(p) = 1 si I(p) 0 si I(p) U.
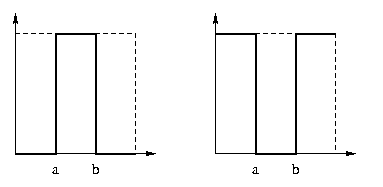
Généralement U est un intervalle [a,b] (l'ensemble des
niveaux de gris compris entre a et b). On parle alors de seuillage
de l'image d'intervalle [a,b]. On prend souvent un intervalle de
la forme [t,g1] ou [g0,t], et on écrit
St pour
S[t,g1], et
S*t pour
S[g0,t] ; donc
St(I) comprendra tous les pixels
p dont le niveau de gris I(p)  t, tandis que
S*t(I) comprendra tous les pixels
p dont le niveau de gris I(p)
t, tandis que
S*t(I) comprendra tous les pixels
p dont le niveau de gris I(p)  t. On appelle généralement
St (resp.,
S*t) le seuillage supérieur
(resp., inférieur) de seuil t. On a la
comparaison suivante entre St(I)
et S*t(I) :
t. On appelle généralement
St (resp.,
S*t) le seuillage supérieur
(resp., inférieur) de seuil t. On a la
comparaison suivante entre St(I)
et S*t(I) :
St(I)(p) = 1 et S*t(I)(p) = 0 pour I(p) > t, 1 1 pour I(p) = t, 0 1 pour I(p) < t.
En fait S*t(I) est le complémentaire de St+1(I).
Quand l'ensemble U est agrandi, il y a plus de pixels sélectionnés, donc SU(I) grandira. En particulier :
S[a,b](I) grandit quand a diminue et b augmente.
St(I) grandit quand t diminue.
S*t(I) grandit quand t augmente.
Le problème principal de toute méthode de seuillage est le choix du seuil (ou de l'intervalle de seuillage). Avec un intervalle trop large, on obtient des faux positifs, c.-à-d. l'image seuillée contient des pixels qui ne font pas partie des objets d'intérêt ; généralement il s'agit de bruit, ou des structures d'une autre nature, qui ont un niveau de gris proche de celui des objets recherchés. Avec un intervalle trop étroit, on obtient des faux négatifs, c.-à-d. certains objets d'intérêt n'apparaissent pas, ou que partiellement, dans l'image seuillée. Nous donnons donc ci-dessous quelques méthodes pour la sélection de l'intervalle de seuillage.
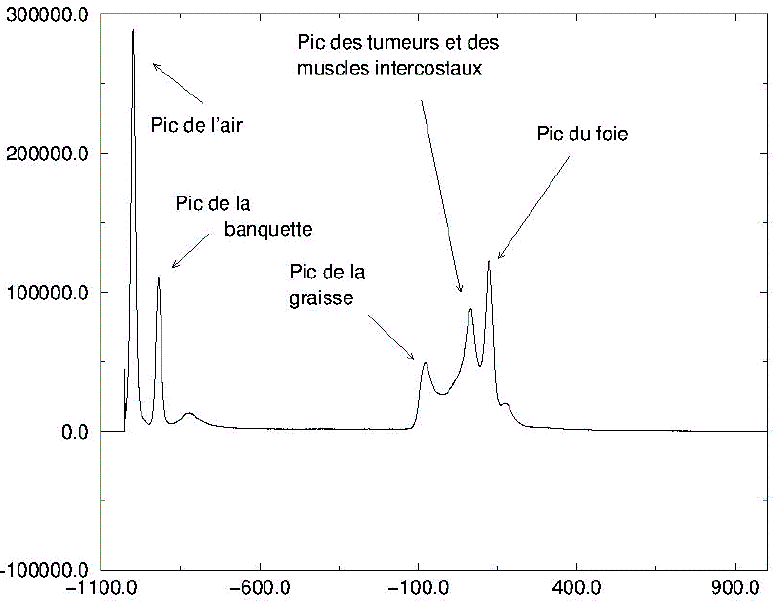
Si les pixels dans les objets d'intérêt ont leurs niveaux de gris proches d'une même valeur v, tandis que ceux dans les autres structures ont presque toujours des niveaux de gris éloignés de v, alors l'histogramme de l'image aura un pic autour de v. C'est ce que nous illustrons ci-dessous dans l'histogramme d'une image scanner 3D de l'abdomen d'un sujet (fournie par l'équipe IRCAD/VIRTUALS) :
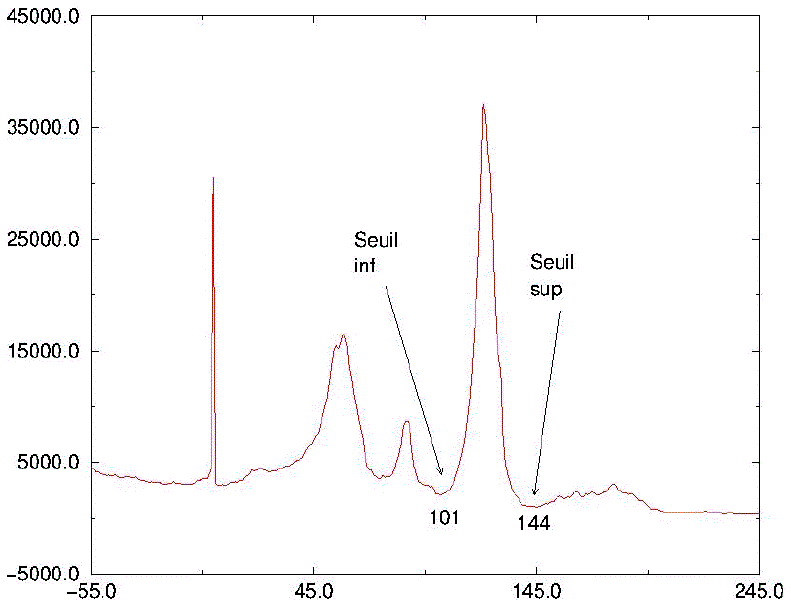
En fait, cet histogramme a été lissé, car la plupart des histogrammes ont un aspect bruité, avec des pics crénelés. On pourra donc sélectionner les bornes de l'intervalle de seuillage [a,b], en prenant dans l'histogramme lissé les deux minima de l'histogramme situés de part et d'autre de la valeur v de référence pour le niveau de gris des objets recherchés. C'est ce que nous illustrons ci-dessous pour l'intervalle de seuillage correspondant au foie dans une image scanner abdominale (également fournie par l'équipe IRCAD/VIRTUALS) :
C'est une méthode qui s'applique normalement pour les seuillages de la forme St et S*t. On choisit une proportion p de pixels de l'image qui devront être sélectionnés par le seuillage (par exemple 50%). Cela donne donc un nombre n = p.|I| de pixels à sélectionner. On prend alors le seuillage St(I) qui comprend les n pixels les plus clairs de l'image I, ou bien le seuillage S*t(I) qui comprend les n pixels les plus sombres de I. En fait, comme l'histogramme est discret, il sera généralement impossible de sélectionner par seuillage exactement n pixels ; on prendra donc t tel que le nombre de pixels sélectionnés dans St(I) ou S*t(I) soit le plus proche de n (par excès ou par défaut).
Pour déterminer t, on se basera sur l'histogramme de
l'image ; en fait on utilisera l'histogramme cumulatif, qui
associe à tout niveau de gris g le nombre CI(g) de
pixels dans la grille ayant un niveau de gris g dans l'image. Donc avec
S*t, on prendra pour t le plus petit g tel
que CI(g) n (ou
bien le plus grand g tel que CI(g) n). Pour St, on
fera de même en prenant l'histogramme cumulatif inverse
CI* (où CI*(g) est le nombre de pixels
dans la grille ayant un niveau de gris g dans l'image) ; on peut aussi utiliser le fait
que St(I) est le
complémentaire de
S*t-1(I), lequel doit donc
comprendre le nombre complémentaire de pixels.
Pour le seuillage S[a,b] d'intervalle [a,b], on doit donner deux proportions (ou pourcentages), par exemple la proportion ps de pixels dont le niveau de gris est < a (trop sombre) et la proportion pc de pixels dont le niveau de gris est > b (trop clair).
Généralement, on affichera en noir les pixels sélectionnés (marqués 1) par le seuillage, et en blanc ceux éliminés (marqués 0) par le seuillage (ou vice-versa). Cela revient à faire un masquage blanc de l'intervalle de seuillage, et en même temps un masquage noir de son complément, comme illustré ci-dessous :